ADVANCES IN PARALLEL COMPUTING
FOR THE YEAR 2000 AND BEYOND
|
Thuy Trong Le Fujitsu America, Inc. High Performance Computing Group 3055 Orchard Drive San Jose, California 95134-2022 E-mail: [email protected] |
Tri Cao Huu San Jose State University Department of Electrical Engineering One Washington Square San Jose, California 95112 E-mail: [email protected] |
Abstract
Computer simulation is a critical technology that play a major role in many areas in scientific and engineering. With the declining in defense budgets in the early 1990s, the U.S. high-performance computer companies has shifted their focus away from scientific computing market toward the business high-performance computer market where the greatest demand is for cost-effective of midrange performance computers. In this market, the performance improvement is emphasized on the price-to-performance ratio rather than on the high performance as in scientific applications.
The recent DOE decision of billion dollars investment in Accelerated Strategic Computing Initiative (ASCI) program has proved the government’s confident in parallel computing technology and also marked the beginning of a great movement in the applications of parallel computers. In September of 1995, DOE announced that it would work with Intel, IBM, and SGI to build three ASCI TFLOP supercomputers. Organizations involve in the operation of the ASCI program mainly include Los Alamos National Laboratory, Lawrence Livermore National Laboratory, Sandia National Laboratory, and five university research centers. ASCI vision is to shift from nuclear test-based method to computational-based methods of ensuring the safety, reliability, and performance of U.S. nuclear weapons stockpile. ASCI plans that by the year 2010, it will develop high-performance codes to support weapons design, production and accident analyses. The program also plans to stimulate the U.S. computer manufacturing industry to create more powerful high-end supercomputing capability and create a computational infrastructure and operating environment that can be accessible and usable.
This paper will practically summary the current technical issues in parallel computing and discusses future technical aspects that must be achieved. The paper will discuss some current available technologies which serve as the basic for future parallel computer developments. The paper will also discuss some main research topics which need to be studied for the developments of the year 2000 parallel computers.
I. INTRODUCTION
The speed of serial computers has steadily increased to match the needs of emerging applications overtime. With the limitation in speed of light, saturation in serial computer speed is not avoidable and using ensemble of processors to solve grant challenge problems is a natural way. Moreover, a cost-performance comparison of serial computers over the last few decades shows the saturation of this curve beyond certain point. With the results of VLSI technology, cost-performance curve of microprocessors became very attractive over serial computers. The idea of connecting microprocessors to form parallel systems is considerably reasonable both in terms of cost-performance and speed.
Fast solution is not the only advantage of parallel computers. Bigger and more complex problems which require too large amount of data for a single CPU memory is also an important factor. Parallel computing permits simulations to be run at finer resolution and physical phenomena can be modeled more realistically. In theory, the concept of parallel computing is not anything else but the applying of multiple CPUs to a single computational problem. In practice parallel computing requires a lot of learning efforts which include parallel computer architectures, parallel models, algorithms and programming, parallel run-time environment, etc.. Different problems can be paralleled to different degrees. In term of performance, some problems can be fully paralleled and others can not. The nature of the problem is the most significant factor to ultimate success or failure in parallel programming.
For more than a decade, lots of efforts have spent for the development of parallel computing in both hardware and software. With the lack of financial supports, research and commercial in high-performance computing areas have slowly decreased in the past few years. The recent announcement of DOE decision on ASCI program has made a turning curve of high-performance computing areas. Although ASCI main vision is to advance the DOE defense program computational capabilities to meet future needs of stockpile stewardship, it surely will accelerate the development of high-performance computing far beyond what may be achieved in the absence of this program.
II. ISSUES IN PARALLEL COMPUTING
Parallel computing can only be used effectively if its technical issues are defined clearly and practically understood. Issues need to be concerned in parallel computing science include the design of parallel computers, parallel algorithms and languages, parallel programming tools and environment, performance evaluation, and parallel applications. Parallel computers should be designed so that they can be scaled up to a large number of processors and are capable of supporting fast communication and data sharing among processors. The resource of a parallel computer will not be used effectively unless there are available parallel algorithms, languages, and methods to evaluate the performance. Parallel programming tools and environment are also very much important in helping parallel program development and shielding users from low-level machine characteristics. Parallel applications are the final target of parallel computing, efficiency and portability of a parallel application are the most to date research topics of parallel computing society.
II.1 Parallel Computer Architectures
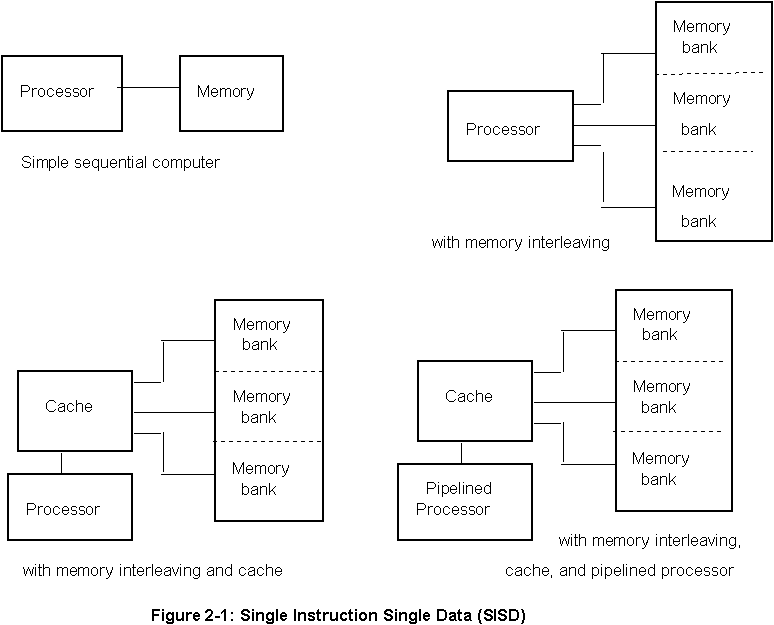
Basically computers can be classified into three exist categories: Single Instruction Single Data Stream (SISD), Single Instruction Multiple Data (SIMD), and Multiple Instruction Multiple Data (MIMD). The SISD or sequential computer model takes a single sequence of instructions and operate on a single sequence of data. A typical sequential computer evolution of this category is shown in Figure 2-1. The speed of SISD computer is limited by the execution rate of instructions and the speed at which information is exchanged between the memory and CPU. The latter can be increased by the implementation of memory interleaving and cache memory and the execution rate can be improved by execution pipelining technique as shown in Figure 2-1. Although these techniques do improve the performance of the computer, limitations are still exist. Cache memories is limited due to hardware technology. Memory interleaving and pipelining are only useful if small set of operations is performed on large arrays of data.
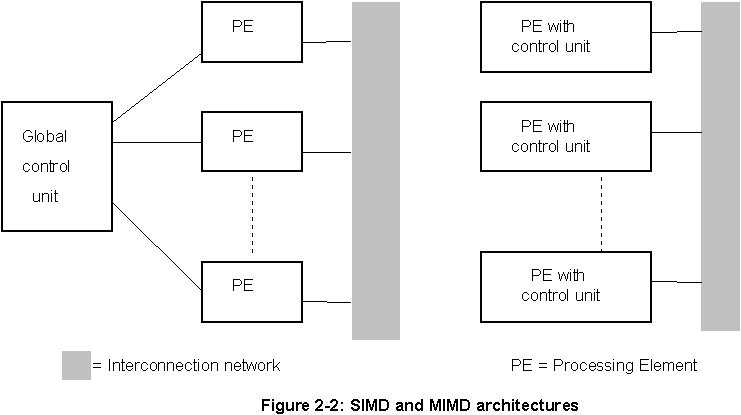
In theory parallel computing is the technique that can speedup the performance without any limit. In practice performance of parallel computers is still limited both by the hardware and the software. The SIMD and MIMD computers are both belong to parallel computer category. As shown in Figure 2-2, a SIMD architecture system has a single control unit dispatches instructions to each processing element in the system. A MIMD architecture system has each control unit in each processing element such that each processor is capable of executing a different program independent of the others in the system.
The SIMD architecture is capable of applying the exact same instruction stream to multiple streams of data simultaneously. For certain classes of problems called data-parallel problems, this architecture is perfectly suited to achieving very high processing rates, as the data can be split into many different independent pieces, and the multiple instruction units can all operate on them at the same time. SIMD architecture is synchronous (lock-step), deterministic, and very well-suited to instruction and operation level parallelism. The architecture can be classified into two distinguish categories called processor array machines and vector pipeline machines. The processor array machines (such as the Connection machine CM-2, the Maspar MP-1) have an instruction dispatcher, a very high-bandwidth internal network, and a very large array of very small-capacity instruction units, each typically capable of operating on only a single bit or nibble (4-bit) data element at a time. Characteristically, many of these are ganged together in order to be able to handle typically encountered data types. The vector pipeline machines (such as the IBM9000, the Cray Y/MP) have only a fairly small number, typically between 1 and 32, of very powerful execution units called vectors because they are specially designed to be able to effectively handle long strings ("vectors") of floating point numbers. The main CPU handles dispatching jobs and associated data to the vector units, and takes care of coordinating whatever has to be done with the results from each, while the vectors themselves concentrate on applying the program they have been loaded with to their own unique slice of the overall data.
The MIMD architecture is capable of running in true "multiple-instruction" mode, with every processor doing something different, or every processor can be given the same code. The latter case is called SPMD "Single Program Multiple Data" and is a generalization of SIMD-style parallelism with much less strict synchronization requirements. The MIMD architecture is capable of being programmed to operate as synchronous or asynchronous, deterministic or non-deterministic, well-suited to block, loop, or subroutine level parallelism, and multiple Instruction or single program. Some examples of MIMD machines are the IBM SP-series, the clusters of workstations/PCs using PVM/MPI, the IBM ES-9000, the KSR, the nCUBE, the Intel Paragon, and the NEC SX-series. Still another computer model which is based on both SIMD and MIMD architectures (such as the CM-5 and the Fujitsu VPP-series) in order to take advantage of the either when the algorithm benefits most from it. In the Fujitsu VPP-series system, each processing element is a vector pipeline computer and these processors are connected together by an internal communication network.
There are many parallel computer models which are classified based on their control mechanism, address-space organization, interconnection network, and granularity of processors. Depend on the memory structure of the system, MIMD architecture is classified into shared memory and distributed memory architectures. In shared memory architecture, the same memory is accessible to multiple processors and synchronization is achieved by controlling tasks’ reading from and writing to the shared memory. The advantage of this type of architecture is the ease of programming but there are many disadvantages to pay off for this. Since multiple processors can access to the same memory, the scalability of the system is limited by number of access pathways to memory and synchronization has to be controlled manually. To improve the performance, each processor can be provided with a local memory and the global memory is shared among all the processors in the system. Depend on the speed of memory accessing, shared memory computers can be classified into the Uniform Memory Access (UMA) or Non-Uniform Memory Access (NUMA) computers. Some examples of shared memory parallel computers are the IBM ES-9000, the SGI Power Challenger, and the Convex systems.
In a distributed memory parallel computer each processor element has its own local memory and synchronization is achieved by the communication between processors via inter-connection network. The major concern in distributed memory architecture is the data decomposition, that is, how to distribute data among processors (local memories) to minimize processor communication. Distributed memory systems can virtually view as "message-passing" and "virtual-shared or distributed-shared memory" models. In message-passing systems, program tasks communicate by explicitly sending/receiving data packages to/from each other. The process of sending/receiving data is specified and controlled by the application program via message-passing libraries (MPI, PVM, etc.) or languages (VPP-Fortran, Linda, etc.) Some examples of message-passing systems are the IBM SP-series, the Fujitsu VPP-Series, and the hypercube machines nCube. The virtual-shared memory systems provide programmer with a shared-memory programming model but the actual design of the hardware and the network is distributed. In this type of system, a very sophisticated address-mapping scheme insures that the entire distributed memory space can be uniquely represented as a single shared resource. The actual communication model is the lowest level and in fact it is the message-passing but it is not accessible to the programmer.
The other class of MIMD computers that based on both shared- and distributed-memory architectures is the Symmetric Multi-Processor (SMP) clusters. A typical SMP system in fact is a cluster of a large groups of nodes as a distributed-memory computer (each node behaves as a processor). Each node in turn has small number of processors (typical 4 or 8 processors) with shared-memory. In practice, SMP clusters should be treated as distributed-memory computers. Programming in SMP clusters is very similar to programming in distributed-memory computers with each processor is a vector processors.
Both the shared- and distributed-memory computers are constructed by connecting processors and memory units using variety of interconnection networks. In shared-memory systems, interconnection network is for the processors to communicate with the global memory. In distributed systems, interconnection network is for processors to communicate each other. Interconnection networks can be classified as static and dynamic interconnection networks. Static networks (direct networks) consist of point-to-point communication links among processors and are typically used in message-passing computers. In dynamic networks (indirect networks), communication links are connected to one another dynamically by the switching elements to establish communication paths. Dynamic networks are typically used in the shared-memory computers. Some examples of static networks include completely-connected network, star connected network, linear array and ring network, mesh network, tree network, and hypercube network. Some examples of dynamic networks include crossbar switching networks, bus-based networks, and multistage interconnection networks.
Parallel computers are also classified based on granularity, i.e., the ratio of the time required for a basic communication operation to the time required for a basic computation. Parallel computers with small granularity are suitable for algorithms requiring frequent communication and the ones with large granularity are suitable for algorithms that do not require frequent communication. The granularity of a parallel computer is define by the number of processors and the speed of each individual processor in the system. Computers with large number of less powerful processors will have small granularity and are called fine-grain computers or Massively Parallel Processors (MPP). In contrast computers with small number of very powerful processors have large granularity and are called coarse-grain computers or multicomputers.
II.2 Some Aspects in Parallel Programming
Creating a parallel program very much depends on finding independent computations that can be executed simultaneously. Currently most of the parallel programmers produce a parallel program in three steps: 1) developing and debugging a sequential program, 2) transform a sequential program into a parallel program, and 3) optimizing the parallel program. This approach is called implicit parallel programming in which mostly data is paralleled. This is because of the sequential nature of the human and also because of the long time training in sequential program developments. The right way for developing an effective parallel program is "everything has to be in parallel initially", that is, the programmers have to explicitly program the code in parallel and there is no sequential-to-parallel step. This requires the development of parallel mathematics, numerical methods, schemes, as well as parallel computational algorithms which is currently under developments.
With the existing of too many well recognized computer codes, the term parallel programming currently includes the conversion of sequential programs into the parallel ones. For many years from the first parallel system was constructed, the parallelization of existing codes has been done largely by manual conversion. Many research and development projects are under funding to develop parallel tools for automatic parallelization. Many current compilers attempt to do some automatic parallelization, especially of do-loops, but the bulk of parallelization is still the realm of parallel programmer. The parallelization of a serial code can involve several actions such as the removal of inhibitors for parallelization, the insertion of constructs or calls to library routines, and the restructure of serial algorithms to the parallel ones.
There are different aspects for developing a parallel program on a shared-memory and a distributed-memory systems. In the shared-memory programming, programmers view their programs as a collection of processes accessing a central pool of shared variables. In the message-passing programming, programmers view their programs as a collection of processes with private local variables and the ability to send and receive data between processes by passing messages. Since most of the shared-memory computers are NUMA architectures, using message-passing programming paradigm on the shared-memory machines in fact improves the performance for many applications.
In some problems many data items are subjected to identical processing and such problems can be parallelized by assigning data elements to various processors, each of which performs identical computations on its data. This type of parallelism called data parallelism is naturally suited to SIMD computers. Data parallelism is not suited to MIMD computers due to the requirement of global synchronization after each instruction. This problem can be solved by the relaxing of synchronous execution of instructions and this leads to another programming model called Single Program Multiple Data (SPMD). In SPMD programming model, each processor executes the same program asynchronously and synchronization takes place only when processors need to exchange data.
The other type of parallelism called control parallelism in which each processor executes different instruction streams simultaneously. This type of parallelism is suited to MIMD computers but not to SIMD computers since it requires multiple instruction streams, and so programming in this model is called Multiple Program Multiple Data (MPMD) model. Although the amount of data parallelism available in a problem increases with the size of the problem, the amount of control parallelism available in a problem is usually independent of the size of the problem and so control parallelism is limited to problem size.
III FUTURE RESEARCH TOPICS IN PARALLEL COMPUTING
As in other sciences and engineering fields, the main issues in parallel computing is to build efficient parallel systems, that is, the large or small systems capable of exploiting greater or smaller degrees of parallelism, as desired, without wasting the resources. This is a very difficult task since different parallel architectures are suitable for different applications. Currently parallel computers on the average can only deliver about ten percent of their peak performance when applied to a wide range of applications. In order to build efficient parallel systems, parallel computing industries should first decide to concentrate on one of the two directions: 1) the fix in hardware and software resources and 2) the variable in parallel computer designs. By fixing the computer hardware and software resources, parallel computing research then facing the problem of how to use the system efficiently for a wide range of applications, and this leads to the mapping problems that must be solved. By designing different parallel systems for different target applications, parallel computing research then facing the problems of computer design, both technically and economically.
Different parallel computer applications require different levels of parallel performance. In term of hardware requirements, the currently industry trends generally satisfy most of current commercial applications except applications for national defense purposes. In term of software requirements, the current industry trends generally do not satisfy most of scientific/engineering problems. Parallel software technologies are too much behind the hardware that hardware resources are used wastefully in most of the cases. Some critical future research in parallel computer hardware include topics related to interconnection networks, interfaces, wide and local networks, and storage peripherals. In term of the software critical future research include topics related to visualization, computational mathematics and algorithms, mesh generations, domain decomposition, scientific data management, programming models, compilers and libraries, development tools, parallel I/O systems, and distributed operating systems software.
The increase in computational power directly relates to the increase in number of connected processors and so the interconnection networks. Achieving high performance becomes significantly more difficult with increases in communication time. For the year 2000, performance at TFLOPS levels seem to be the target. These high performance levels require thousands of interconnected CPUs and so inter-communication becomes one of critical factors to achieve the high performance. The current inter-network and interface technologies can not satisfy the requirements of TFLOPS systems. Moreover, very often the requirements in computational power of an application directly relates to the requirements in the data size, high performance networks for data transfer and large storage capacity are also critical topics needed to be studied. The current technology in these areas only can satisfy applications in the order of GFLOPS.
In term of visualization, parallel computer designers/developers will soon need advanced techniques to analyze the large data sets in high performance computations. These should include scaleable parallel visualization methods; hierarchical methods for representation and visualization; data-mining techniques for feature localization; integration with data archiving, retrieval, and analysis systems; and scaleable visualization methods for performance monitoring and for debugging of large parallel applications.
In term of computational mathematics and algorithms, scaleable numerical methods and code frameworks are needed to enable scientific simulations. The current numerical methods although adequate for most 2-D simulations will not scale to 3-D problems of future interests. Numerical methods topics of interest include preconditioned iterative methods for sparse linear systems of equations, methods for large systems of nonlinear equations, methods for time-dependent differential equations, parallel adaptive mesh refinement techniques and support libraries, flexible code frameworks for building physics codes, and application-aware communication routines.
The interests in analysis of problems of complex geometries also require sophisticated, intuitive, and easy to use graphical mesh generation tools. Mesh generation needs to be interactive, with the scientist able to specify some individual points numerically, and others through a set of interpreted mathematical-like expressions. The largest single source of scientist error is running the wrong problem, caused by incorrect specification of the mesh, or incorrect selection of boundary conditions, physics models and parameters. It would be very useful to provide an automated comparison of problem generators to ensure that deviations from accepted settings and parameters are intentional. Expert system software or on-line help to assist in problem generation and parameter selection are desirable. These systems should also provide assistance to the scientist to optimize the domain decomposition of the problem. Scientific data management (SDM) technology is also required to provide the tools and supporting infrastructure to organize, navigate and manage large data sets. An effective SDM framework should seamlessly integrate databases, mass storage systems, networking, visualization, and computing resources in a manner that hides the complexity of the underlying system from the scientist performing data analysis.
The current message passing programming models require application developers to explicitly manage data layout across memory hierarchies from on-chip caches to archival storage. There is a need for portable higher level abstractions that simplify the process of parallel programming by automating data layout and hiding low level architectural details such as memory hierarchies. Applications should be able to adapt quickly and reliably as new computational requirements arise and are scaleable and easily portable to successive generations of platforms. High level programming models and abstractions are required that facilitate code reuse, reduce code complexity, and abstract away low level details necessary to achieve performance on a particular architecture. The current models for message passing are too low level to achieve this objective and promising work is underway in object-oriented frameworks and HPF but much work remains. Four programming models are currently of interest are: 1) the message passing (MPI) everywhere (shared and/or distributed memory), 2) the standard language extensions or compiler directives for shared memory parallelism and the message passing for distributed, 3) the explicit threads for shared and the message passing for distributed, and 4) the high level language and run-time (object) constructs to present a serial programming model and a global data space over shared and/or distributed memory.
Compilers are also required to generate highly optimized code that effectively utilizes multiple levels of memory. Run-time libraries that provide efficient and scaleable methods for numerical analysis, adaptive mesh refinement, load leveling, mesh partitioning and parallel I/O are also needed. Performance measurement, debugging, quality control, verification, and validation of parallel codes becomes increasingly difficult as code size and complexity increases and so the process of code development for complex parallel architectures needs to be made simpler. Tools to assist in this process need to have common capabilities and user interfaces across variable platforms. Networking infrastructure and the tool design must make tools usable remotely over a wide area network.
Several areas in operating system research also need to be addressed to support the scaleable distributed computing environment. To support the degree of parallelism required (e.g. millions of threads), mechanisms for efficient thread creation, scheduling, and destruction will be needed. High performance, scaleable, portable local and distributed file systems and end-to-end parallel I/O mechanisms are needed. There are many challenging resource management issues that need to be addressed to integrate the entire system, from the computing node and local disks to multiple nodes and archival storage to integration of the sharing of data and computer resources in the distributed computing.
Research is also needed on both operating and programming system environments that provide services and tools to support the transparent creation, use, and maintenance of distributed applications in a heterogeneous computing environment. In order for the system to distribute resources to users within a parallel distributed computing environment with heterogeneous machine types (e.g. single processor, SMP, MPP), operating systems will have to control single machine usage and parallel usage spread over many machines. Currently no system exists that provides this coordination while delivering specific allocations to projects. Distributed resource management is needed capable of managing the closely interacting processing and storage resources at all levels.
IV CONCLUSION
Parallelism is to reduce the turn around time but even increase the CPU time due to overhead and increase the required memory due to duplicated data and instructions. Writing and debugging a parallel program is much more complicated than a sequential program, at least an order-of-magnitude. Different architectures, different programming models are suitable for different applications and so the characteristics of the applications should make decision for the selection of parallel hardware architecture and also the parallelization of the applications.
Performance at TFLOPS levels will be required for the year 2000 parallel computers. Since most of the current technologies, especially in the software areas, are only work for the GFLOPS systems, many technical issues in high performance computing need to be addressed as discussed in Section III. Beside the semiconductor technology, parallel computer designers and developers also have to aware of the rapid movements in other technologies such as analog optical, superconductivity, biotechnology, and neural networks. While semiconductor technology will continue to be used, these new technologies will sooner or later be available to parallel processor designers and developers.
REFERENCES
1. O. Serlin, The Serlin Report On Parallel Processing, No.54, pp.8-13, November 1991.
2. The Accelerated Strategic Computing Initiative Report, Lawrence Livermore National Laboratory, 1996.
3. Dan I. Moldovan, Parallel Processing, From Applications to Systems, Morgan Kaufmann Publishers, 1993.
4. Introduction to Parallel Processing, Cornell Theory Center Workshop, 1997.